Bias and Algorithms
How algorithms become biased and shape our behavior
What is an algorithm and what is bias
The definition of algorithms and bias
The simplest form of an algorithm is a set of instructions that produce some intended output.
The simplest form of an algorithm is a set of instructions that produce some intended output. However, with the introduction of “big data” and machine learning, we’ve seen algorithms start to use massive amounts of data to predict what should be output.
Computers today collect all sorts of data on their users. For example what links you click on, your screentime, and who you follow on social media are all data that help machine learning algorithms make decisions.
The definition of bias is prejudice in favor of a certain group, person, or thing often in an unfair manner.
Bias often hurts disadvantaged groups such as people of color, members of the LGBTQ community, and those with disabilities.
Why do we use algorithms?
Algorithms are fundamental to all types of electronics. The timer on your microwave uses an algorithm to calculate how long to cook your food. The lock on your door uses an algorithm to be unlocked with the correct key.
While these sorts of algorithms are simple, more complicated algorithms are built on machine learning and large sources of data. These types of algorithms reduce the need for human-decisions and increase efficiency on a large scale. In short, modern big-data algorithms make processes more efficient. They have become fundamental to all types of electronics and media we use today.
What are some well known algorithms
Each of these social media platforms have had infamous histories with the collection of user-data for their algorithms. Their ability to make predictions about their users brings up concerns over privacy and bias regarding preferred content.
The algorithms behind these social media platforms push out certain content that they assume we would be interested in. This can create confirmation bias as we are only viewing videos, posts, and images that support our perceptions.
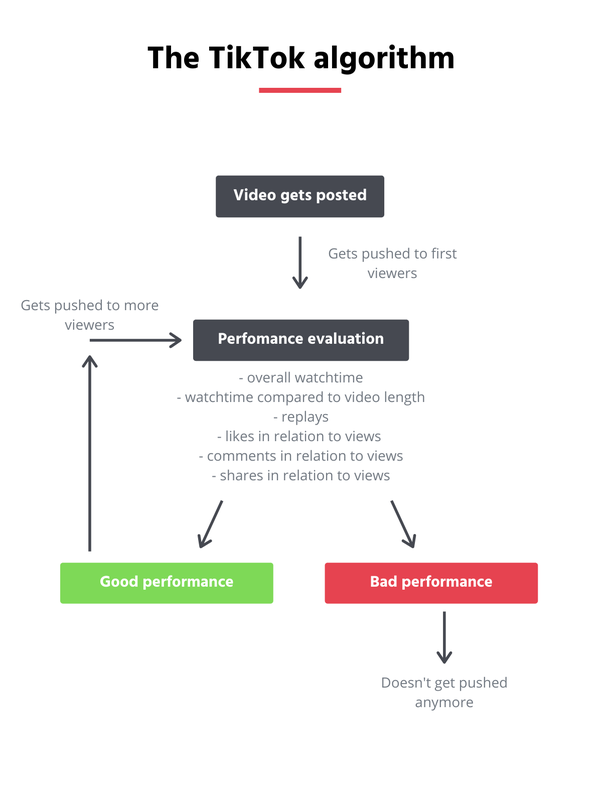
Tik Tok's Algorithm
The following are factors that are at play when Tik Tok recommends videos on your For You Page.
User interactions
Captions
Hashtags
Video audios
Watch time of videos
Language preferences
Country/Location
Device type
Popularity of creators
Follower count
What factors are tracked?
All of these factors are tracked when using the app. Unlike other social media apps, TikTok uses both active and passive forms of user interaction. Like other platforms, who you like, follow, and comment on are tracked and used to provide reccomendations.
Passive forms of interaction
However, passive forms of interaction such as watch time, looking at profiles, the number of times a video is watched, and the amount of videos watched from a certain creator are used to track users' interests. While not inherently problematic, this secretive tracking is able to fine tune the algorithm to a specific user.
Knowledge bubbles
The accuracy and efficieny of the algorithm creates a "knowledge bubble" for users. As the app becomes a way to spread news and activism, users won't be exposed to alternative view points. As users swipe, they only see content that confirms their viewpoints which can lead to division and misinformation.
Content censoring
Every social media platform censors content. Graphic content and hate speech are banned on most social media platforms and will be taken down for violating guidelines. However, the mode of censorship through TikTok's algorithm has been problematic in the past. While other platforms have reactive content moderation, TikTok moderates content before it's even posted and shown on the For You page. Humans and algorithms tag content and put them into specific categories. If a video is deemed to violate the guidelines, it will be taken down without notifying the user that the video was censored. This secrecy sparked outrage when internal documents showed political content such as the Black Lives Matter movement and the Tiananmen Square protests was taken down. Creators from Black activists to users deemed "unattractive" were being supressed and not having videos pushed out. Although TikTok claimed this was unintentional, the bias infiltrated the algorithm and favored certain content over others.
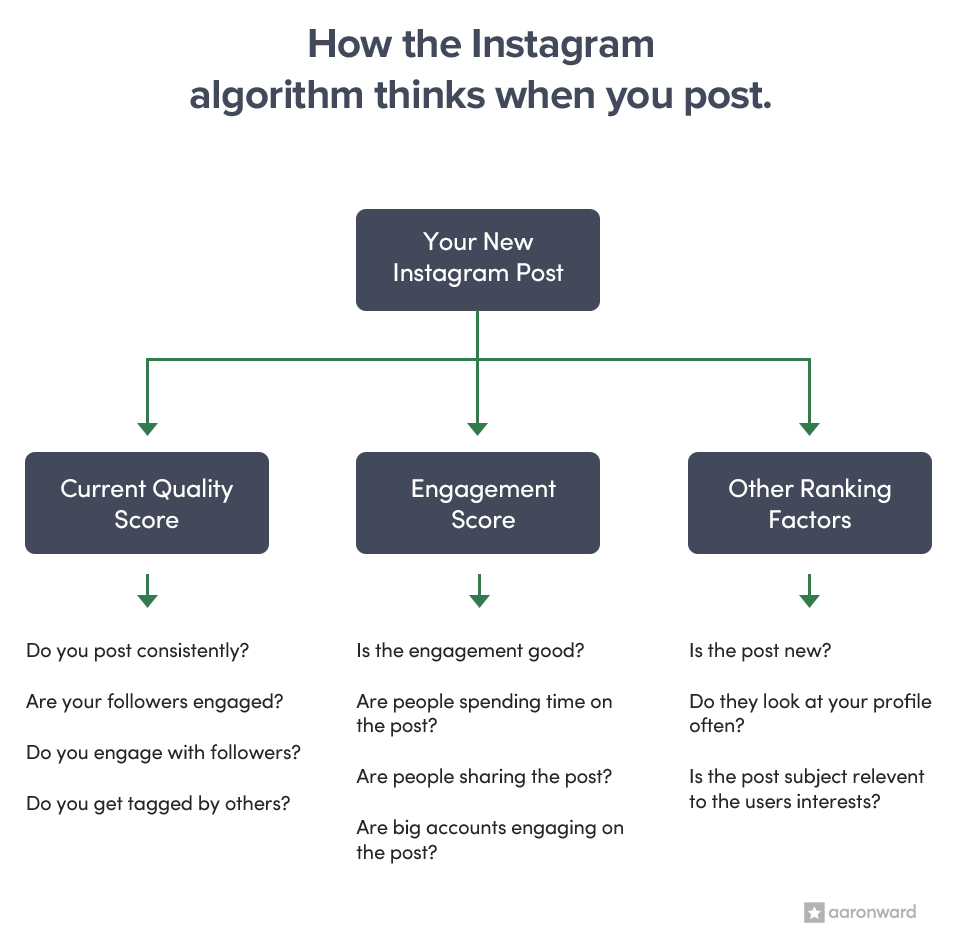
Instagram's Algorithm
Instagram takes the following factors into account for their algorithm
Instagram uses multiple algorithms
Information about the post: how many people have liked it, when it was posted, the location tag (if used). If it is a popular post, it’s likely to end up on your feed
Information about the person who posted: how much interaction the person gets from other users. If more people like the person’s post or have interacted with their profile, the higher the chance the person’s post ends up on your feed.
History of interaction with poster: how often you’ve interacted with the poster in the past indicates how interested you’d be in the person’s new post.
Interaction with the post: how long you spend looking at the post, whether or not you comment/like/save, if you tap on the person’s profile all contribute to whether or not the post ends up on your feed.
Interactions between users: what content people you follow are interested in, accounts your friends follow, etc all contribute to building the explore page. Posts you’ve liked before but don’t follow the account often show up on the explore page.
Similar to TikTok's algorithm, Instagram uses active information from users in the app. It tracks things such as who you follow, who you interact with most, what posts you like, and how long you spend viewing a post.
Using a combination of algorithms, Instagram is able to create a close network of of people and posts. As Instagram is used for political and activist content,
confirmation bias affects all users.
Google's Algorithm
Google is the world's most used search engine. What makes Google such an efficient search engine is that it curates its search results
to each user. This is done by tracking search history and what links users click on.
By collecting user data, the Google algorithm biases your search results to what it thinks it knows about you. This creates an "information bubble"
and furthers ideological divides. Google is a major source of news and current information and these curated search results can have dangerous consequences.
How has bias been built into algorithms?
Survival of the best fit
Try this interactive game that puts you in the position of using a biased algorithm. It teaches you how inherent bias and systemic inequalities
create bias through an example of resume screenings.
Click here to play the game!
Historical human bias
Algorithms are created by humans. Humans carry bias, whether intentional or not. Therefore, the data used to train machine learning algorithms will often reflect both bias from the current programmer as well as historical bias within our society as a whole.
The data used to train machine learning algorithms will reflect bias from the past. Often, developers of these algorithms rely on data
from the past. The problem is that data taken from the past contains historical prejudice. A recruitment algorithm that scans applicants' resumes
can easily become biased against women because historical data tends to show more male applicants being hired due to fewer women in the work force
and facing workforce discrimination.
A Princeton study found that an algorithm that detected word associations associated words like "men" with the maths and sciences while words like "women"
were associated with the arts. This association could easily find its way into algorithms and group men and women into categories that aren't representative
of individual character.
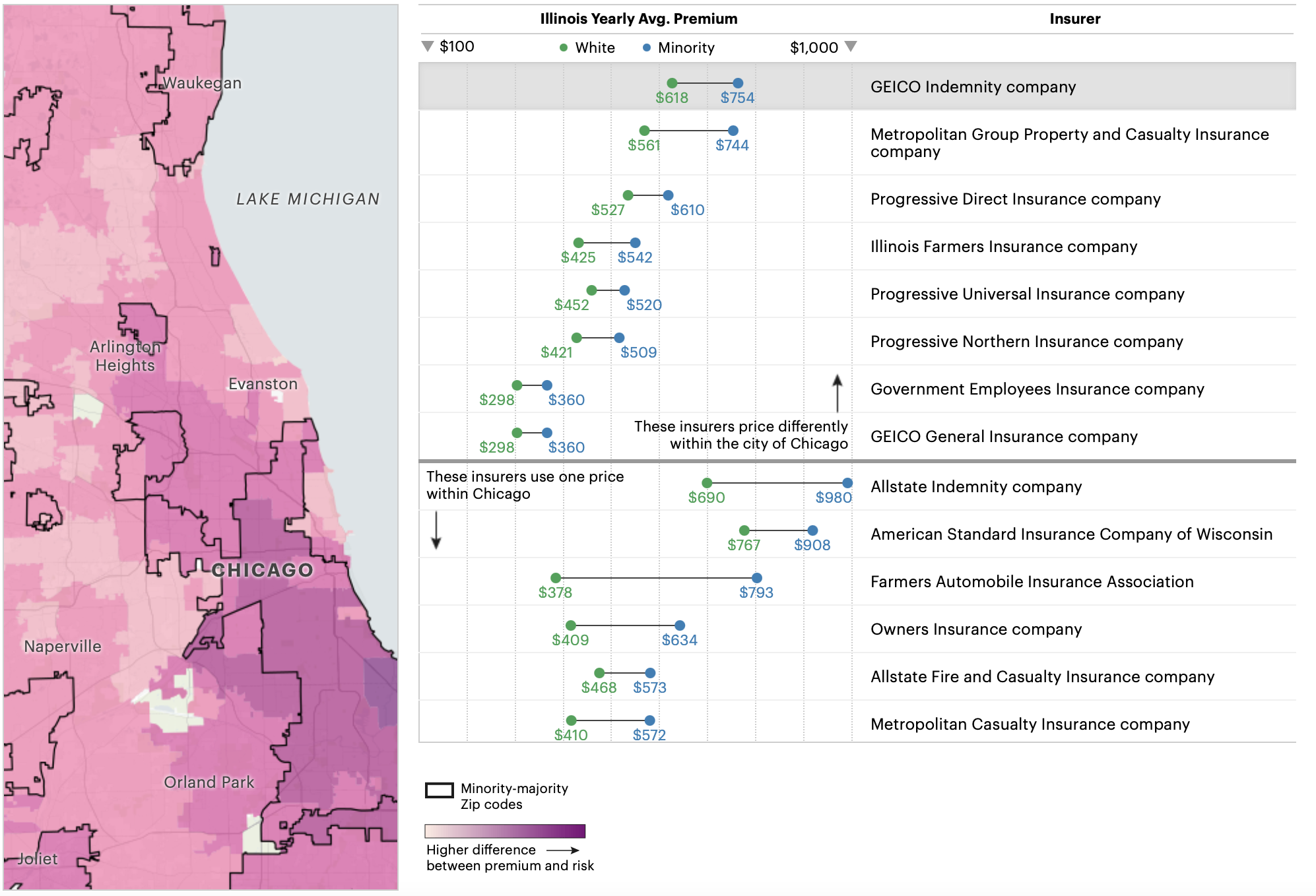
One example of historical human biases in algorithms can be found in auto insurance rates in Chicago. Auto insurance agencies use algorithms
to set insurance rates for their customers. A research group through ProPublica found that a Black man living in a zip code with a greater non-white population
had to pay higher insurance rates than a white man in a white-majority zip code. Even though the risk for accidents and expense of accidents was higher in the white-majority
zip code, the non-white majority zip codes had insurance rates 50% higher.
Historically, zip codes with majority BIPOC (Black, Indigenous, people of color) populations were discriminated against. Banks refused loans and there was minimal investment in these communities.
This practice is called redlining and allowed large wealth gaps to form between white and minority communities. In the 1970s and 1980s auto insurers
continued to scrutinize insuring minorities and charged higher rates. The systemic bias in this data had been used in modern algorithms which has lead to bias.
The disparities in insurance rates makes it more difficult for minorities to access economic opportunities. For some, owning a car is too expensive which limits
where they can find employment. For those that pay for a car, income has to be stretched and limits how minorities can spend their money.
Incomplete and unrepresentative data
Today, advanced algorithms rely on data to train and make predictions. It's easy for the data being used to not be entirely representative. When data
used to train algorithms isn't accurate, it creates bias in the algorithm.

Joy Buolamwini is a researcher at MIT and was conducting research using a facial recognition software. She found that the technology
was not accurately detecting her face. The more she tested it, Buolamwini found that it was having more difficulty detecting faces with
darker complexions, and especially Black womens' faces.
Facial recognition software works by taking a taking a face and having the computer analyze key details about the face. For example, the AI would
detect features such as the width and angles of facial features. The analysis is compared to a database of photographs that have been used to train the algorithm.
If the database of photos isn't representative of all types of people, the algorithms used to identify faces will be biased. This was the case for Buolamwini's algorithm.
In many cases the photos used to train the algorithm are mostly white and male. This means that the software has experience detecting white male faces, but struggles anyone else.
In Joy Buolamwini's facial recognition software, it could detect white male faces 90% of the time but could only accurately detect Black females
20-34% of the time. These facial recogniton softwares become dangerous when used in situations such as policing. As police try to find potential matches to crimes,
an algorithm with that struggles to detect people of color will be more likely to misidentify them.
If you're interested in further information, Buolamwini created a documentary on her experience called Coded Bias. The film can be watched on Netflix. Buolamwini also gives
a good Ted Talk on her experiences.
Watch the Ted Talk here!